Pregnancy+
Feeld
亮点
- 3 个月内对 5 款应用进行了 12 次 A/B 测试
- 测试期间 MRR 增长 28%
- 整个流程由一名非营销人员完成
AppDevLabs 开发订阅类应用,涵盖工具、体育和媒体领域。产品组合中有五款应用,排名靠前的一两款会受到重点关注,其余的则一直沿用上线时设定的定价——有的已经好几个月没有调整,有的甚至更久。
这五款应用的组合 MRR 达到数万美元。三个月后,经过 12 次实验且零新增人员,MRR 增长了 28%。
这种情况在小型工作室中并不罕见。一个人负责所有五款应用的数据分析、定价决策和实验。旗舰产品得到了优化,其余应用则停留在无人质疑的价格上,每天都在产生低于潜力的收入。团队心知肚明,只是没有找到解决办法。
运营五款应用却只优化一款的困境
团队已经在使用 Adapty 的 A/B 测试。问题在于如何决定测试什么、在哪款应用上测试、以及按什么顺序进行。
五款应用分布在不同品类,各有不同的用户群体和竞争环境,可能的实验方案数量庞大。要提高工具类应用的价格?还是给娱乐类应用增加一个层级?或者改变媒体类应用的付费墙布局?每个决策都需要团队没有时间去做的竞品调研。

因此实验要么没有进行,要么进展缓慢——一次只做一个,选哪款应用全凭直觉。整个产品组合就这样停滞不前。
从无从下手到有优先级的实验队列
Autopilot 为团队提供了每款应用的起点:一份简短的优先测试清单,按预期影响排序,并附有每项建议背后的逻辑。
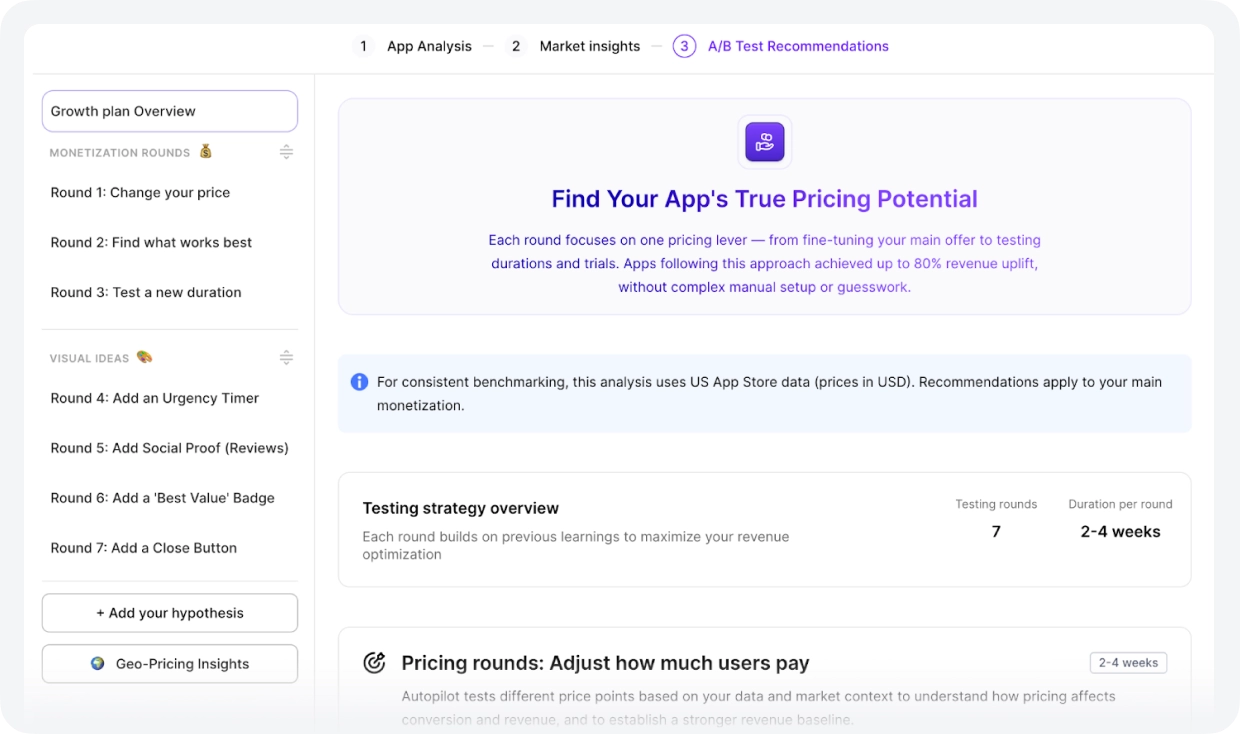
为了生成这份清单,Autopilot 分析了每款应用的当前定价,将其与同品类竞品进行对标,并与行业平均水平进行比较。输出结果针对每款应用在其市场中的具体位置量身定制。
两个变化立竿见影。团队不再需要手动调研同类应用的收费情况。实验也不再在两轮之间停滞——完成一个测试,立即获得下一个建议。对于一个人管理五款应用来说,第二点和第一点同样重要。
工作室的角色发生了转变。他们不再需要琢磨测试什么,而是审批建议并执行上线。Autopilot 负责分析、对标和排序。AppDevLabs 做最终决策。
三个月全组合测试的实际情况
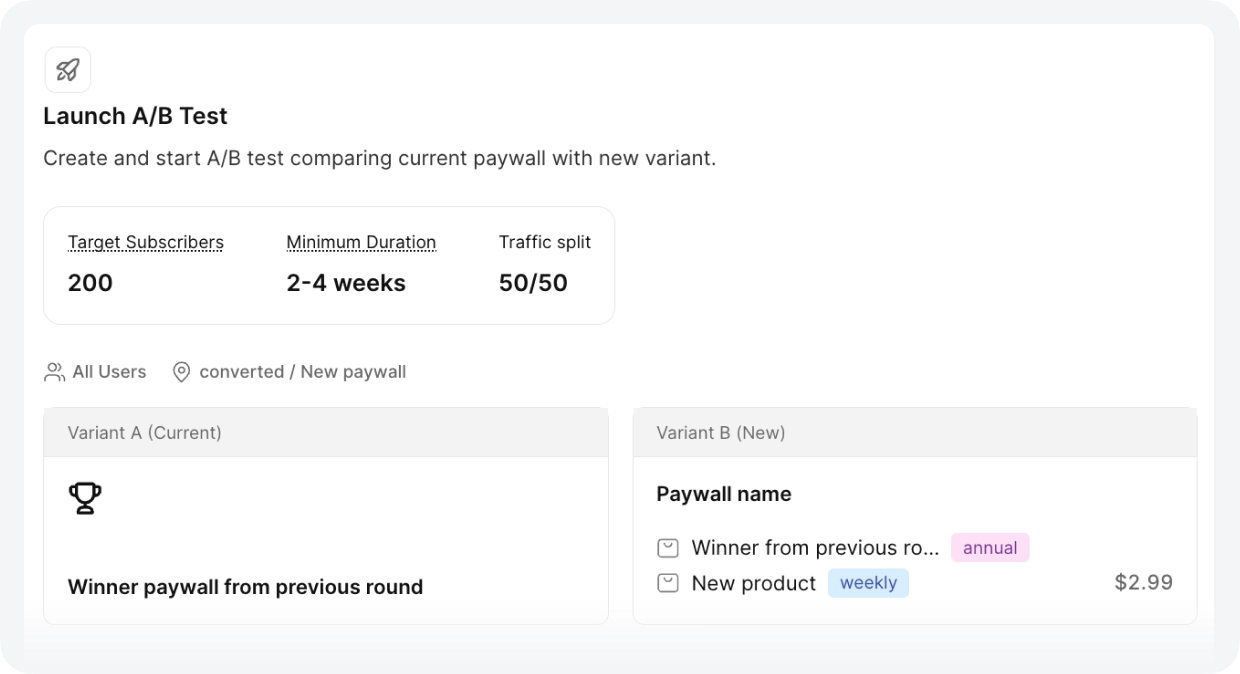
从 2025 年 12 月到 2026 年 2 月,团队在五款应用上共进行了 12 次 A/B 测试。整个流程由一个人管理。旗舰娱乐应用经历了三轮完整的序贯测试,每轮都在前一轮的胜出方案基础上进行。
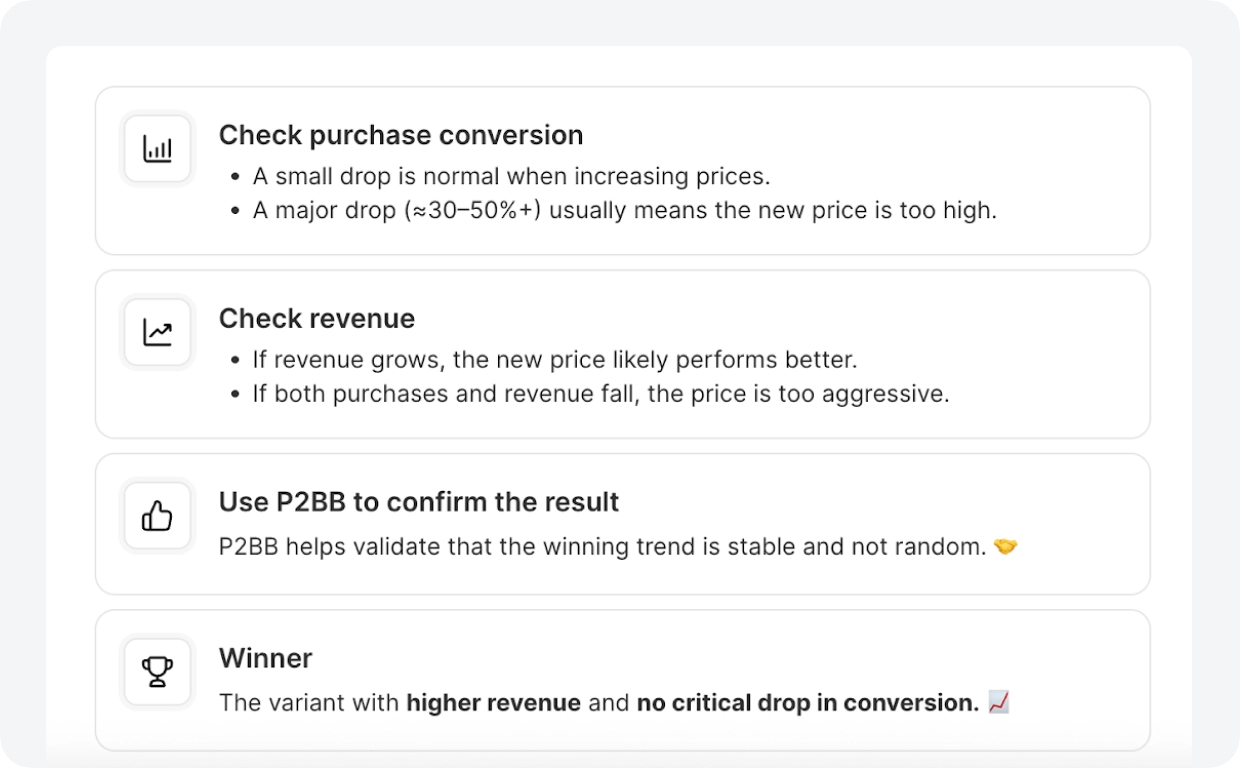
在达到统计显著性的 8 次测试中,5 次取得了正向结果。63% 的胜率——对于定价类工作来说表现强劲,毕竟即使微小的变动也可能影响转化率。
更重要的数据是:Autopilot 为每款应用给出了不同的建议。一款需要提价 67%,另一款需要降价,还有一款需要新增一个层级。如果没有为每款应用配备专门的分析师,工作室不可能在五款应用上手动完成这些工作——光是竞品调研就要花好几周。Autopilot 在后台持续运行,自动呈现每款应用真正需要的调整方案。
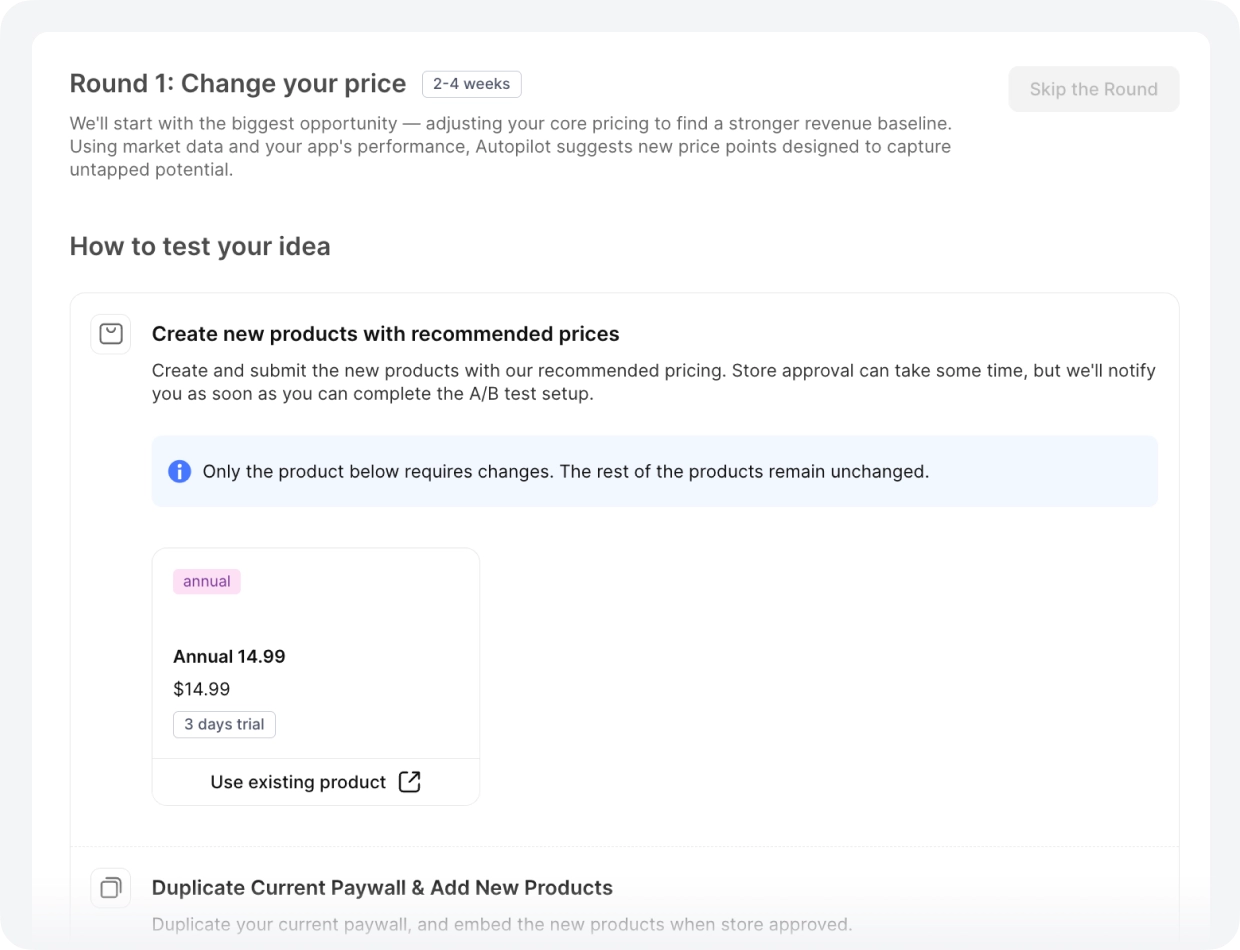
旗舰娱乐应用(约 $30K MRR):每笔年度交易少收了 $10
该应用的年度方案定价为 $14.99。Autopilot 的竞品分析显示,该品类的平均价格为 $24.99。团队每位订阅用户少收了 $10,低于市场承受范围。他们测试了 $24.99 的定价,转化率保持稳定,提价方案成功落地。
同一款应用:团队以为用户倾向年付,实际上用户在选择周付
在年度方案提价成功后,Autopilot 建议新增 $3.99 的周付方案。团队以 79/21 的比例在年付和周付之间进行了测试。但更有价值的发现来自后续变化:每当周付价格变动时,年付购买量会朝相反方向变化。
工具类应用:相比所有竞品低了 $5
在竞品定价为 $14.99 的品类中,这款应用仅售 $9.99/年,每笔年度交易少收了 $5。Autopilot 标记了这一问题。团队测试了 $14.99 的定价——提价 50%。测试以 99% 的概率胜出,转化率未受影响。
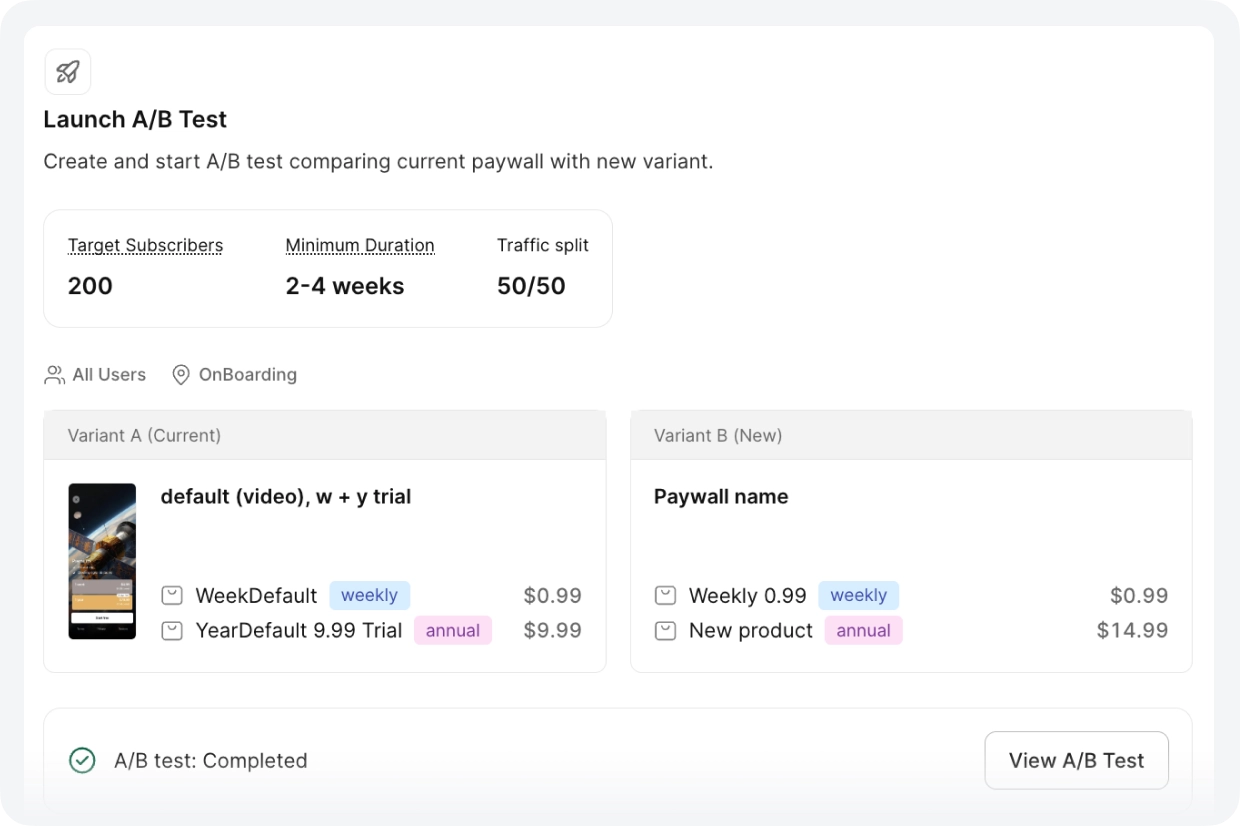
媒体类应用:定价偏高,Autopilot 指出了这一点
这款应用年费 $19.99,高于品类平均水平。建议方向相反:测试 $14.99。更多用户以更低的价格订阅,总收入随之增加。406 次购买,95% 的概率为最优方案。
同一款媒体应用:团队为何不再假设定价可以跨市场通用
在欧洲将周付价格从 $1.99 提高到 $2.99。同样的调整在英国市场的娱乐应用上却失败了。团队现在按市场分别进行测试,而不是套用一个全球统一价格,因为数据表明欧洲和英国用户的付费意愿差异无法靠经验推断。
迭代方法
没有任何单一测试是决定性的,关键在于节奏。每次完成的实验都为下一次提供了依据:胜出方案成为新的基准,Autopilot 生成新的挑战方案。旗舰应用在三个月内经历了三轮测试——先是新增周付层级,然后是年度定价调整,接着是付费墙排列实验。每一轮都在前一轮的基础上递进。
对于一个人管理五款应用来说,实验之间的间隔才是真正的瓶颈,而不是执行测试本身或决定下一步做什么。Autopilot 消除了这个间隔。
相同的逻辑,不同的市场,不同的结果
在取得初步成功后,团队使用 Adapty 的分群功能在不同地区测试不同的价格。美国是主要的测试市场。当美国市场得出结论后,团队会针对英国或欧洲用户进行类似的测试。有时结果一致,有时则不然。
按国家分别测试,让团队能够基于各市场自身的数据来定价,而不是将整个产品组合押注在单一的全球假设上。
一个人三个月能完成什么
AppDevLabs 没有组建增长团队,也没有聘请定价顾问。他们将 Autopilot 接入现有工作流,由它处理那些阻碍实验推进的环节:竞品分析、行业对标,以及决定下一步测试什么。
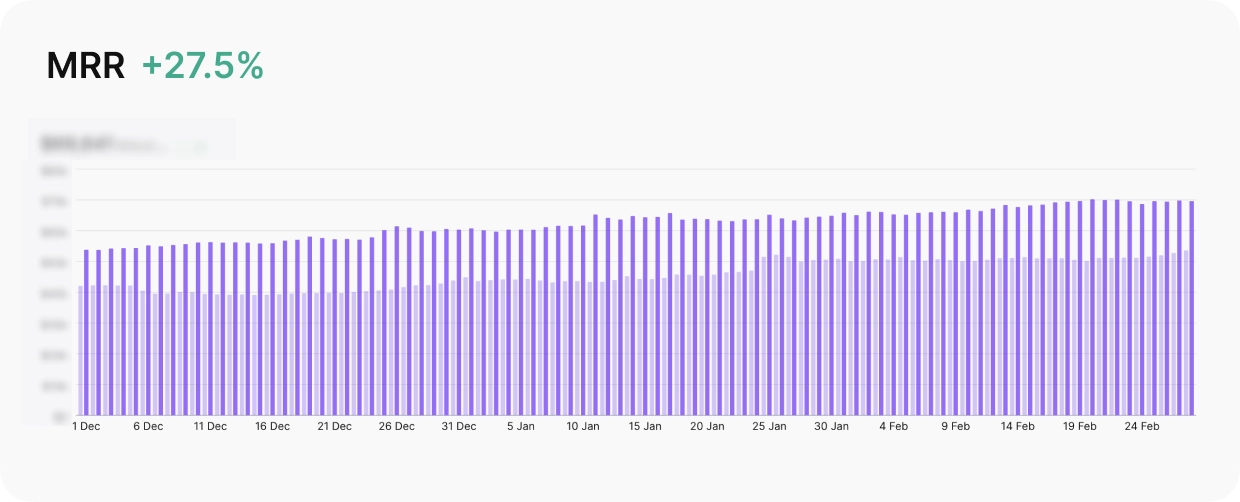
团队负责审批,结果自然呈现。五款应用共进行了 12 次实验,63% 取得正向结果。测试期间 MRR 增长 28%。全部由一个非营销背景的人管理。