SaaS is often invisible to those who use it. In practice, though, this software often plays such a crucial role in how your product works and how users perceive it that sometimes your app just can’t be the same without it.
Adapty is one of those invisible yet critical types of SaaS. We handle a key piece of mobile app infrastructure: monetization — specifically, processing and validating subscriptions and in-app purchases. We can’t let clients down because Adapty makes or breaks their users’ experience. That’s why reliability is absolutely critical for us. It’s an inherent attribute of what we build rather than just a feature.

It ain’t rocket science, but it’s no walk in the park either
Let’s break down just how complex the system is that we need to keep stable. Spoiler: pretty damn complex. Mobile app subscriptions aren’t as simple as they might seem at first glance. It’s rarely just “person subscribes, uses the service, then unsubscribes.” Nope. Subscriptions almost always follow more complicated scenarios, and the number of these scenarios can be enormous.
Imagine a new user comes in and starts a 7-day trial on iOS. Here’s what happens next:
- On day five, their partner adds them to a family subscription that’s set up through Google Play.
- The initial trial converts anyway because, according to Apple’s rules, participating in Apple Family Sharing doesn’t cancel active trials.
- The user ends up with two active subscriptions — one of their own and one through the family account.
- They cancel the Apple subscription and get a refund.
- The webhook misfires and marks the subscription as “canceled,” even though the user still has access to the app through family sharing on Android.
Already a pretty messy situation, but it can easily get worse. What happens if one day the payment doesn’t go through on time, and the family subscription enters “account hold” status? Or if the subscription owner switches to an annual plan because they saw a 40% discount? And then our user decides to buy themselves a separate iOS subscription through a different promotional offer?
The result is a mess:
- One user across two platforms.
- Three pricing tiers and two active entitlements.
- A grace period clashing with a refund.
- Whatever problem this particular family is having with organizing their subscriptions.
But seriously, all these events need to be handled correctly, not just on the app level, but on the backend too.
Why cross-platform subscription management is even harder
Correctly processing subscription logic can be challenging even within one ecosystem, but if you have a cross-platform app, it becomes an order of magnitude harder. Apple and Google have different receipt formats, different subscription states, and different field names for the same concepts. The same goes for refunds, cancellations, subscription upgrades, the billing retry procedure, and webhook logic.
So if you’re building subscription infrastructure, you need to support two parallel systems while maintaining a unified picture. And you need that unified picture, especially if you want to build quality analytics. Constructing a working infrastructure is already no small task, but layering quality analytics on top of it? That’s “Nightmare” difficulty level.
That’s what we’re dealing with — and why we designed Adapty’s infrastructure the way we did.
Why we chose a hybrid infrastructure over pure cloud services
Before creating Adapty, the company’s founders were dealing with subscription management logic in other apps, so they knew from day one which landmines to avoid. Infrastructure at Adapty has always been in the spotlight, and we built in backup mechanisms and error handling right into the architecture design stage.
One fundamental thing about Adapty’s infrastructure is that we consciously decided against relying on cloud services too much from the very beginning. It sounds boring, but this decision was largely dictated by cost; at our traffic volumes, we’d be getting notorious cloud services bills for hundreds of thousands of dollars. That’s important, but far from the only reason. As we saw in 2025, cloud services can go down, and the bigger they are, the more painful it is.
Of course, Adapty uses clouds, but the main part of our backend consists of on-prem servers with Kubernetes. On top of that, we use a CDN in more than 300 locations worldwide, including Europe, the US, and China. This allows us to display paywalls and send analytics events faster, while also improving the experience for users with poor internet connections — paywalls load quicker since the response comes from the geographically closest server.
The CDN also helps take the load off our infrastructure and shields it from external attacks thanks to traffic distribution, filtering, and the CDN’s own built-in security measures. Last but not least, we use the CDN for paywall caching (read more on how exactly below). If Adapty’s backend goes down, the user will still see the paywall because the app pulls the cached version directly from the CDN.
We started using CDNs more than two years ago and have kept expanding their functionality. For example, it now helps us run A/B tests: since paywalls are stored on CDN servers all over the world, we can load paywalls in A/B tests 300-500 milliseconds faster than processing them on our backend.
You might reasonably ask: What’s the point of not depending on clouds if you depend on a CDN provider? As the Cloudflare outage in November 2025 showed, failures of these platforms can hit just as hard as the massive AWS collapse did a month earlier. Overall, Adapty’s approach is not to depend on third-party services, but where we do, we don’t put all our eggs in one basket.
We already use two independent Cloudflare environments. When the SDK loads, the config is pulled dynamically. If certain URLs in Cloudflare are unavailable, we have built-in URL rotation, and dynamic loading allows us to avoid requests to non-working URLs. Additionally, in the next couple of months, we’ll launch a backup setup with a different CDN provider, creating a fully dedicated stack with independent storage, CDN, and DNS.
How we deliver paywalls and process subscriptions step-by-step
Let’s look at how Adapty’s infrastructure works, using a basic chain of events as an example: from loading a paywall to activating a subscription. You’ll see for yourself what kicks in on the backend side, what can go wrong, and how we protect against it.
Fetching paywalls and products
This is the most important and simultaneously most complex part from an infrastructure standpoint. One rule: the paywall absolutely must load. For subscription-based apps, a paywall is as important as a cash register in a store. Or the front door? Anyway, I hope the analogy is clear enough.
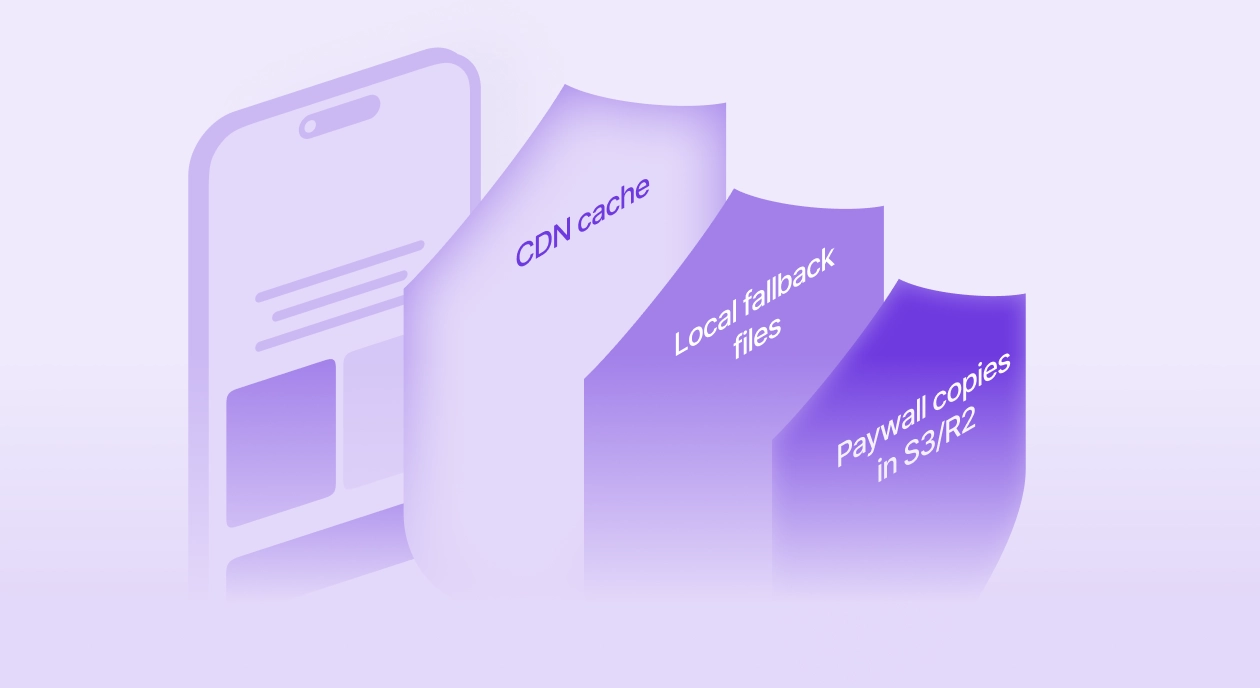
When loading a paywall, the Adapty SDK first makes an HTTP request to our server. By default, the SDK returns the paywall upon receiving a successful backend response. All requests to the backend are routed through a CDN with a caching layer. If the paywall is cached on the CDN, it will be returned directly from there. The CDN cache activates when there are more than 5 requests per minute from the same location, with profiles sharing the same segments. This cache remains valid for up to 20 minutes.
If there’s no cache on the CDN, the request will be handled by the backend. However, the paywall received from the server will be cached on the CDN, and all subsequent requests from the same location should retrieve a cached response. But what if there’s no cache on the CDN and our backend is unavailable? In that case, you can configure fallback paywalls — they’ll back you up.
In case those fail or don’t exist, we have a special fallback backend deployed, and the paywall will load from there. And if even that becomes unavailable, local fallback paywalls kick in. You can download these yourself and include them in the app build, so they’re stored locally on the user’s device.
Adapty has laid down safety nets everywhere, so the paywall will load and products will display even if a user opens the app completely offline. We cache paywalls in such a way that this works even for a user who just installed the app and launches it for the first time.
After the paywall is loaded, a separate method pulls products from the store. It uses native mobile libraries and doesn’t interact with the Adapty backend.
Processing the payment
This next step happens entirely on Apple’s or Google’s side. We can’t possibly safeguard against errors here, but we trust these companies to handle payments reliably.
Whether the transaction completes or fails, the result is returned to the app, and the Adapty backend picks it up from there. If the payment is successful, we validate the receipt to ensure the authenticity of the purchase.
Granting the subscription entitlement
Next, the backend must process the received response and assign the user the appropriate role, activating the subscription. This is a key stage, and we can’t drop the ball here either, because otherwise an awkward situation occurs: payment went through, but the subscription didn’t activate. Pretty unpleasant, to say the least.
Adapty SDK addresses this by saving entitlements locally for those very rare cases when our backend is unreachable. The user experience stays intact.
How we maintain uptime through 24/7 monitoring and incident response
Adapty strives to maintain 99.99% uptime. The mythic four nines. The problem is that a 99.99% SLA allows for exactly 52.6 minutes of downtime per year, which is totally achievable but difficult if the timeframe isn’t long enough or you don’t have a Google-tier budget. The AWS and Cloudflare outages of 2025, which we mentioned earlier, reiterated how you can do everything right and still get hurt.
Our stability data is completely transparent and available on our status page. Sometimes, we deal with downtime, but usually, it’s barely noticeable to users. The last serious incident in November 2025 resulted in only 7% of requests being retried due to CDN issues. In 2025, Adapty’s API had only 30 minutes of major outages, and we’re proud of that number — it’s the best in the industry.
Adapty holds SOC 2 Type II certification, which confirms we’ve built robust availability monitoring. We have a dedicated team of 20 people who uphold infrastructure stability. The system is monitored 24/7 by both software and engineers on duty. We use Grafana, pinging our infrastructure from eight global checkpoints every 15 seconds, tracking response codes and latency. If a ping fails, an alert fires. If that alert isn’t resolved in 5 minutes, it escalates to DevOps. Should DevOps fail to answer, the Head of Engineering is paged directly.
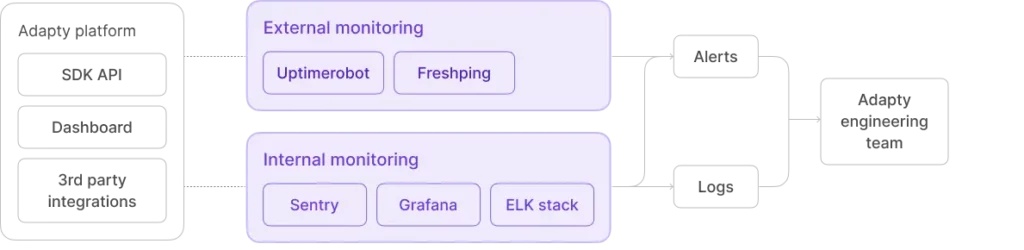
Beyond monitoring, we’re constantly optimizing. After each incident, we work to prevent it from happening again in the future: introducing additional protective measures, updating the SDK, fixing errors where they occurred.
Maintaining 99.99% uptime is simply business as usual at Adapty. Any downtime will cost our clients money and directly challenge our mission to help app owners maximize their revenue. The store must be open at all times.